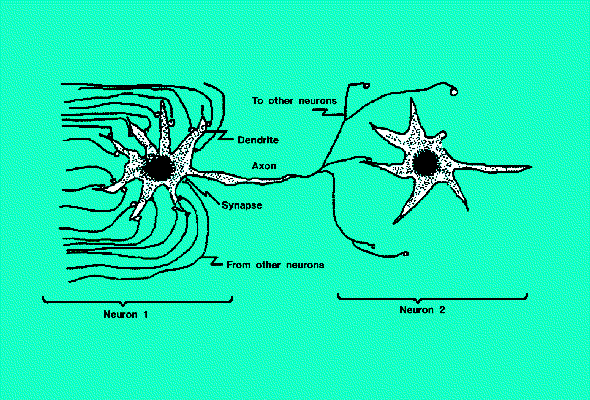
Figure 1. Neurons

This article introduces the basic concepts of Artificial Neural Networks and the related work that is currently being carried out at ESRIN in the field of document classification and searching. Some of the authors' ideas on the future directions that these techniques might take are also presented.
The completeness and timeliness of information are vital elements for modern organisations, whether they be large intergovernmental agencies or small enterprises. The amount of information now available to them has become huge, and the growth trend is nearly exponential. This information-rich situation is actually a draw-back since traditional search systems are starting to reach their limits. The use of these older systems is getting more and more difficult for the users who want to retrieve relevant information, as well as for the maintainers who have to carry out such activities as indexing, document classification and thesaurus maintenance. Two key requirements for solving this problem are:
Artificial Neural Networks have qualities that can be exploited successfully in order to fulfil these requirements. Documentation handling tasks are usually characterised by a lack of pre-defined rules; moreover, they can often be reduced to classification tasks. Research in the last 10 years has shown that Artificial Neural Networks are particularly good at dealing with such ill-structured classification tasks.
Nowadays, computers have astonishing processing powers and yet people are still much better at performing complex but everyday tasks like recognising an image or grasping an object. The reason for this superiority probably lies in the architecture of the human brain.
Study of artificial analogues of the structure of the human brain was pioneered by McCulloch and Pitts, who in 1943 proposed a model for its basic component, the 'neuron' (Fig. 1). The neuron can be represented as a cell body, the soma, with a single output fibre called the 'axon'. The axon propagates electrical pulses to other neurons or other structures such as muscles. The neuron receives its input from about 10(exp 4)other neurons. The junctions, where input is received, are called 'synapses'.
Figure 1. Neurons
The average human brain is likely to contain more than 10(exp 11) neurons. It is their interaction that produces the well- known, if often incomprehensible, phenomenon of 'human behaviour'.
Biological processes in the neurons are generally much slower than the analogous electronic processes in computers. For example, the maximum frequency of impulses that can be generated by a spiking neuron is less than 1000 per second. Modern microprocessors operate at frequencies of hundreds of millions of cycles per second. In the human brain, however, a huge number of strongly interconnected neurons work in parallel without centralised control. That enables the high-speed solution of certain tasks, as well as providing beneficial characteristics like fault-tolerance and the ability to learn and to generalise.
McCulloch and Pitts' studies suggested the possibility that devices can be constructed to imitate the operations of the human brain in certain respects. Such systems are generally termed 'Artificial Neural Networks'. In the sixties, B. Widrow proposed the model of an artificial neuron known as 'ADALINE', which constitutes the building block of nearly all artificial neural networks. ADALINE is an adaptive linear combiner cascaded with a threshold component (Fig. 2).

Figure 2. ADALINE
At time k, the output Y(k) is a function f(S(k)) of the linear combination of the n input components X(ik) . The output is
Y(k) = f (W(ik) X(ik) - W(0k) X(0k)
where the function f( ) can be of different kinds, e.g. a linear, step, ramp or sigmoid function. The factors W(ik) are called 'weights'. During the training process, these weights are modified by a learning algorithm.
According to I. Aleksander, Artificial Neural Networks are: 'networks of adaptable nodes which, through a process of learning from task examples, store experiential knowledge and make it available for use'. It has been proven that a network with at least two layers of interconnected neurons can reproduce any function, provided that the number of neurons and weights is large enough. In other words, the input/output behaviour of any system, including computers and probably the human brain, can be reproduced by such networks. If we leave the problem of simulating human beings to speculative philosophers for the moment, it is certainly true that whatever can be done by a computer can also be done by an Artificial Neural Network, and vice versa. As matter of fact, Artificial Neural Networks can be implemented using traditional Von Neumann computers.
The reason for the explosion in interest in the scientific community in Artificial Neural Networks can be found in the advantages offered by their different architecture. Traditional computers are instructed via programs. Even the Artificial Intelligence systems are based on programs. Basically, these programs encode rules or 'relationships' between symbols representing real-world objects. In Artificial Neural Networks, the knowledge is not encoded by a programmer into a program, but is embedded in the weights of the neurons. Whilst Expert Systems and Knowledge-Based Systems try to emulate human conceptual mechanisms at a high level, Artificial Neural Networks try to simulate these mechanisms at a lower level. They attempt to reproduce not only the input/output behaviour of the human brain, but also its internal structure. Knowledge is then stored in a non-symbolic fine-grained way. The weights can be set through a learning process, the goal of which is to obtain values which give the network the desired input/output behaviour.
Learning can be either 'supervised' or 'unsupervised'. Supervised learning is a process that incorporates an external teacher. The network is given a set of training patterns and the outputs are compared with desired values. The weights are modified in order to minimise the output error. Supervised algorithms rely on the principle of minimal disturbance, trying to reduce the output error with minimal disturbance to responses already learned. There are two kinds of such algorithms:
Two examples of algorithms of the first kind are the Widrow- Hoff delta rule, and the perceptron rule. An example of an algorithm of the second kind is back-propagation, the algorithm which almost single-handedly revived research into neural networks.
Unsupervised learning is a process that incorporates no external teacher; it is used, for instance, for building Self- Organising Maps, i.e. networks which take sets of input objects, represented by N-dimensional vectors, and map them into a topological space of some chosen dimensionality (often two- dimensional).
Besides the ability to learn through training, a second desirable characteristic of Artificial Neural Networks is their ability to generalise. Once trained, they can often provide the appropriate output even when receiving an input that is (slightly) different from the inputs for which they have been explicitly trained. In effect, they can answer questions that were never asked before.
Based on different training methodologies and different ways of arranging neurons in layers and linking them together, several alternative network paradigms have been proposed. Each of them exhibits slightly different properties which can be optimally matched to specific applications. On the whole, Artificial Neural Networks have been most successfully applied to problems in pattern recognition, adaptive control and business analysis. In general, they perform very successfully when dealing with ill- structured classification tasks.
The tasks involved in handling and using document collections, namely, indexing, classification, thesaurus construction and search, are characterised by a lack of well-defined rules and algorithms to be used for their general solution. In general, they can be regarded as input/output classification tasks. Document classification, for instance, is based on the idea that similar documents should be relevant for the same query. Indexing is the act of describing or identifying a document in terms of its subject content. Thesauri and semantic networks are built by clustering similar terms into common classes and linking these classes with appropriate relations. The search process itself links a user query with the relevant documents of the collection. The common factor is a classification process that associates documents and terms of the collection in different ways.
All of these tasks require the exploitation of a good deal of knowledge about the content of the information and, as a consequence, are usually performed by human operators. Several attempts have been made to execute them in an automatic or semi- automatic way by adopting Artificial Intelligence techniques and, in particular, Expert and Knowledge-Based Systems. However, the need to encode explicitly the knowledge such systems require is often a stumbling block for their full exploitation. Artificial Neural Network techniques are a viable alternative, since the information they encode is learned from the raw data or a specification of the desired transformations.
ESRIN is currently carrying out a research activity with the objectives of:
The reasons for this choice of technical orientation are as follows:
Basically, the prototype will provide two functions. Firstly, it will assist inexperienced users in accessing information through queries, dealing particularly with the need to allow users to go beyond the literal terms that are in their original query. This it will do by analysing the document collection and using the pattern of word occurrence to generalise the initial user query via an implicit thesaurus coded within the neural network. The system can suggest new terms related to those in the initial query, or carry out directly a search trying to match the semantic patterns of the query and of the documents.
Secondly, the system is meant to classify the documents into subject-related groups. These groups can be used for browsing when the user does not immediately start out with a well-defined information need, or does not know the exact content of the document collection. The cluster labels can also be incorporated into queries to broaden or narrow a search. From the several Artificial Neural Network paradigms that have been proposed in the literature, the following have been chosen and evaluated during the programme:
Of these four options, only the first and the last proved to offer useful functionality. In the final prototype, an Oja Network is exploited to produce the thesaurus used for the explicit or implicit query expansion. A hierarchical implementation of the Kohonen Network is used for producing the clusters of subject-related documents.
Preliminary results
A preliminary version
of the system is being developed for the ESA Microgravity
Database, which is a collection of 975 documents and some
associated images. The collection has been reformulated for this
application, removing the image files from the catalogue and
converting the collection to run under the UNIX version of the
Ful/Text search engine produced by Fulcrum Inc.
First of all, a special dictionary of 2962 terms has been developed for the microgravity collection, some examples being:
Each document has then been coded using the occurrence count of the word stems (included in the dictionary) in that document. The resulting vectors have been transformed using a vector pre- processing operation. A variety of pre-processing procedures, which alter the weighting associated with each word stem and compensate for differences in document length, have been evaluated.
A training set has been generated of pre-processed word stem vectors (in the case of the Microgravity Database this included all the documents in the collection) and this has been used to train the unsupervised Hebbian network. The resulting network acts as a data compression process, squeezing the 2962 word stem element vector into a 100-element semantic pattern vector. This process compensates for 'noise' in the documents (the spurious use of words unrelated to document subject), and generalises a query beyond the small set of words that it might contain.
Figure 3 shows the document density of the microgravity collection for two of the semantic patterns extracted by the Hebbian network. The large peak is an unfortunate artifact of the collection (all the documents here have an identical 'dummy' body, indicating that the results of the experiment are not yet available; these documents appear very similar to the system, differing only in the wording of their titles).

Figure 3. Density distribution of documents from the Microgravity
Database, plotted according to two of the extracted semantic
patterns
The Hebbian network is used in several ways:
Explicit query expansion
The user enters either
single words, or a collection of words, and is provided with a
set of other words which are associated with that word or query.
Some examples from the microgravity collection are:
Blood:
Electrophoresis:
Implicit query expansion
All of the documents in
a collection are coded as their semantic patterns. A user can
enter query and the query can be directly matched against the
semantic patterns of the documents. In this way, the user is
supplied not only with those documents in which words from their
queries occur, but also with documents which are similar to
these. The following is an example query that hopefully makes
this clear:
The original query is the single word 'art', and the six best- matched documents are:
The first three are clearly related and all contain the word 'art' within their title, abstract or body. The next three documents do not contain the word 'art', but represent documents in which techniques similar to those used in the first two (sculpture using glass spheres) are described.
Self-Organising Map
The other part of the system is
a network which clusters documents into a hierarchy of subject-
related categories. A Kohonen's self-organising topological map
receives the documents as input (represented by the semantic
vectors produced by the Hebbian network) and initially produces
a small number of clusters (about 16); each cluster is then sub-
clustered if it exceeds user-specified size. Each cluster is also
described by labels that can be included in standard Boolean
queries. The relation-ships between the top-level clusters for
the Microgravity Database are illustrated in Figure 4.
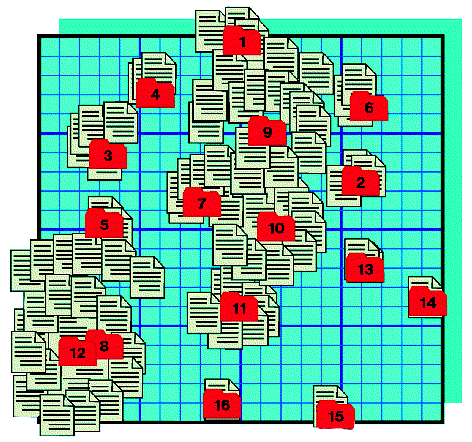
Figure 4. Relative semantic distances of top-level clusters in
the Microgravity Database
The clusters are:
The clusters (8 & 12) with word descriptions 'Synthesized Soon Yet Concern Ha' represent all the documents with the identical dummy body (these words all occur in that body). Subclusters of these clusters do divide the documents using the differences in their titles.
Some example documents from a cluster, showing how well they represent divisions based on subject, are given in the following list - the documents are from cluster 6 'Culture Cell Centrifugal Lymphocyte G' and clearly represent biological experiments conducted in zero gravity:
Other clusters similarly represent fairly clear subject divisions. However, not all the divisions represent a subject selection which one might automatically make; for example, three papers are listed together because they all use hypodermic syringes as part of the experimental procedure.
If users have a pre-defined subject division and wish their collection to match this, then a supervised neural-network approach will match their expectations better. The advantage that the whole unsupervised approach adopted in this work has, though, is that the entire process of constructing the system can be performed with minimal user intervention beyond setting up the initial options.
The future
Based on the encouraging
preliminary results of the project, the authors believe that it
will be relatively easy to incorporate the systems described here
into a number of operational applications at ESRIN. For instance,
the electronic version of the paper that you are just reading
could be soon searchable with a neural system, and it could be
possible to get hold of it with a query that does not necessarily
include the words 'neural networks', but does include, for
instance, the words 'fuzzy search'. Moreover, research should
continue in directions that are bound to return excellent results
by complementing and improving the existing tools for document
classification and search. Basically, the following areas need
to be explored:
Finally, we would like to stress the importance of Artificial Neural Networks in the Internet environment. There we find, on a worldwide scale, the same problems that single organisations face because of the huge amount of potentially available documentation and the difficulty in searching and retrieving the relevant portion for a specific task. Two applications will have to be considered in the near future:



 ESA Bulletin Nr. 87.
ESA Bulletin Nr. 87.