Software - efficient and robust algorithms
Visual attention models could form a successful strategy for reducing the computational effort of computer vision algorithms. The central idea of visual attention models is that they devote most of the processing to the most relevant parts of the image. However, the main challenge is to automatically determine what is ‘relevant’. Several models have been devised that can determine the relevant parts of an image, but many of them extensively process the entire image for determining regions of interest, inadvertently still leading to a large computational burden [1, 2, 3].
In order to achieve a higher computational efficiency, many attention models perform visual tasks on the basis of a restricted number of local samples [4, 5, 6, 7]. In particular, these studies focus on informed sampling, in which the information from the current sample is used to select the next. This can lead to large computational efficiencies, but also often creates a challenging Partially Observable Markov Decision Problem (POMDP). Such a POMDP is currently difficult to solve, and the mentioned studies either make strong assumptions on the task [4] or have to train a model for each different task [6].
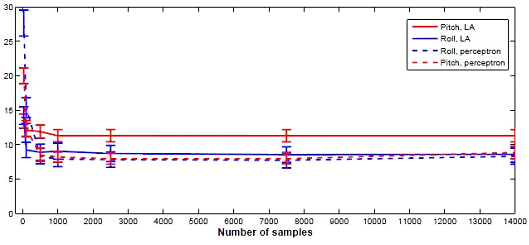
In this study the more straightforward strategy of random sampling is employed. It has been demonstrated that in some cases random sampling suffices to obtain speedups in the order of a 100 times with an unnoticeable cost in accuracy [8, 9, 10, 11]. Below a figure illustrates this for an application of pitch and roll estimation of an Unmanned Air Vehicle that processes local image samples to find the horizon line. The y-axis represents the absolute error in each estimate, the x-axis the number of samples, with full sampling on the far right. It can be observed that peak performance is reached by 1000 samples and after this the performance does not noticeably improve. Extracting only 1000 samples results in a speed-up of 14 times for a small image of 160 x 120 pixels (a border of 10 pixels is used in these specific experiments).
References
- Itti, Laurent, Christof Koch, and Ernst Niebur. 1998. “A Model of Saliency-Based Visual Attention for Rapid Scene Analysis.” IEEE Transactions on Pattern Analysis and Machine Intelligence 20 (11): 1254–59
- Rajashekar, Umesh, Lawrence K Cormack, and Alan C Bovik. 2003. “Image Features That Draw Fixations.” In Image Processing, 2003. ICIP 2003. Proceedings. 2003 International Conference On, 3:III–313 IEEE
- Torralba, Antonio, Aude Oliva, Monica S Castelhano, and John M Henderson. 2006. “Contextual Guidance of Eye Movements and Attention in Real-World Scenes: the Role of Global Features in Object Search.” Psychological Review 113 (4): 766
- Denzler, Joachim, and Christopher M Brown. 2002. “Information Theoretic Sensor Data Selection for Active Object Recognition and State Estimation.” IEEE Transactions on Pattern Analysis & Machine Intelligence, no. 2: 145–57
- Sprague, Nathan, and Dana Ballard. 2004. “Eye Movements for Reward Maximization.” In Advances in Neural Information Processing Systems, 1467–74
- Croon, Guido de, Eric O Postma, and H Jaap van den Herik. 2006. “A Situated Model for Sensory–Motor Coordination in Gaze Control.” Pattern Recognition Letters 27 (11): 1181–90
- Jodogne, SR, and Justus H Piater. 2007. “Closed-Loop Learning of Visual Control Policies.” Journal of Artificial Intelligence Research 28: 349–91
- Xu, Lei, Erkki Oja, and Pekka Kultanen. 1990. “A New Curve Detection Method: Randomized Hough Transform (RHT).” Pattern Recognition Letters 11 (5): 331–38
- Shotton, Jamie, John Winn, Carsten Rother, and Antonio Criminisi. 2006. “Textonboost: Joint Appearance, Shape and Context Modeling for Multi-Class Object Recognition and Segmentation.” In European Conference on Computer Vision, 1–15 Springer
- Barnes, Connelly, Eli Shechtman, Adam Finkelstein, and Dan B Goldman. 2009. “PatchMatch: A Randomized Correspondence Algorithm for Structural Image Editing.” ACM Transactions on Graphics (ToG) 28 (3): 24
- De Croon, GCHE, E De Weerdt, C De Wagter, and BDW Remes. 2010. “The Appearance Variation Cue for Obstacle Avoidance.” In Robotics and Biomimetics (ROBIO), 2010 IEEE International Conference On, 1606–11 IEEE